近年来随着深度摄像机和多摄像头系统的出现,多视角三维人体姿态估计逐渐成为三维人体姿态估计领域的最热门研究方向之一。多视角三维人体姿态估计能够通过利用多个视角的数据,来补充在遮挡、相机运动等复杂情况下缺失的关节点位置信息,减轻单视角三维人体姿态估计存在的深度模糊问题。但在实际应用的非限定环境下,受场景背景、相机拍摄角度、光照、遮挡等复杂因素的影响,不同视角的图像信息间存在很大的视觉表征差异,导致跨视角有效特征提取和融合十分具有挑战性。
重庆研究院研究团队针对许多现有的多视角三维人体姿态估计方法存在忽略关节点多维度隐含信息、依赖特定场景的相机参数、语义特征挖掘不足等问题,研究了基于深度语义图编码器和基于渐进性时空融合的多视角三维人体姿态估计方法。该研究通过提取描述人体关节点丰富空间结构信息的语义图嵌入特征,构建实现不同特征间动态交互和融合的空间语义图编码器以及跨视角时空特征融合方法,充分挖掘不同视角关节点隐含的深层语义知识,增强姿态特征的表征性。
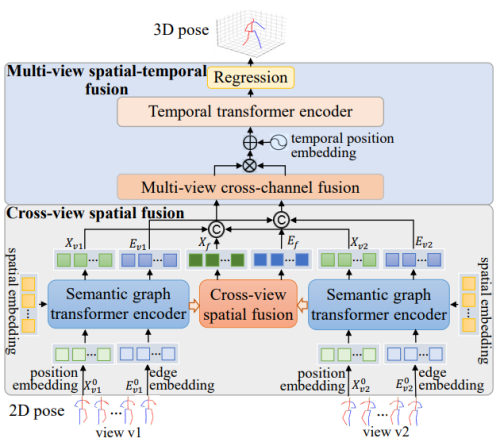
方法框架图
该研究在不依赖相机外参的情况下,有效减轻了深度模糊问题,提升了三维人体姿态估计性能。相关成果发表在人工智能顶会AAAI Conference on Artificial Intelligence(CCF A类)和计算机图形学与多媒体顶会ACM International Conference on Multimedia(CCF A类)上。
上述工作得到国家自然科学基金项目的支持。
相关论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/28549
https://dl.acm.org/doi/abs/10.1145/3581783.3612098